


大数据培训课程分享:MapReduce经验杂谈十则
今天想和大家简要总结一下在千锋大数据培训课程做的一个总结,关于MapReduce的相关知识点,因为学识浅薄,可能会有遗漏的的地方,欢迎各位大佬批评指正!
下面是我个人认为非常值得注意的几处知识点,希望能为大家的学习提供便利。
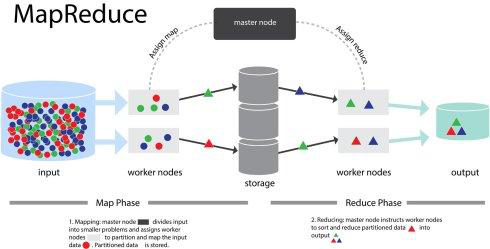
1. HDFS上的文件以行读取,其中key是行中首字母的起始位置,value是该行的文本内容,一行为一对KV键值对。
2. 通过FileInputFormat将文件切分成split块,FileInputFormat只会划分比block大的部分。切割完毕后通过TextInputFormat对split块中的每行记录解析为K1V1键值对。
3. 一个split块对应一个mapper task任务,map接收K1V1键值对后执行map方法,后输出新的K2V2键值对。
4. K2V2键值对添加到环形缓冲区中,当数据量达到80%(默认数据,可以使用参数mapreduce.map.sort.spill.percent修改)之后,这80%环形区会触发溢出操作,然后被封锁,mappertask会向剩余部分继续写入数据。同时会对写完的数据执行partitioner(分区)操作,然后对不同分区中的数据进行排序分组(sort)操作,最后对分组后的数据归约(combiner,通过Key进行归并,减少reduce的负担)。
5. 每发生一次溢出操作就会在磁盘中生成换一个磁盘文件,当磁盘文件写入完毕后,环形缓冲区中的封锁区会清空数据,继续接收数据写入。
6.mapper task的数据全部写出完毕后,会将多个磁盘文件及内存中多余的数据写出到一个本地磁盘文件中。
7.此时会通知APPMaster完成map task,当完成数量达到5%时,就启动reduce task任务。
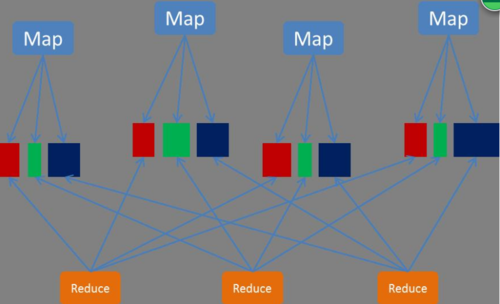
8. reduce生成fetcher线程组(默认5个)将不同分区的的数据copy到不同的reduce节点上。(一个mapper上的分区可能会被发送到多个reduce,同样一个reduce也会接收来自不同的mapper的分区)
9.fetcher线程组将数据写入内存的过程中,内存满75%时,也会发生溢出操作,触发sort和merge操作,最后生成一个磁盘文件(merge操作一般是从内存到磁盘,最后再从磁盘到磁盘)
10. 最后磁盘文件的数据会被分组group来提供给reduce方法处理。根据 FileOutputFormat写入目标文件里。
综上,为MapReuce的细节部分,这部分操作大家比较了解,但是马虎之下容易实现操作性的错误,简要记录十点,望大家多多留意,大数据时代,我们无法安然避世,就业的压力摆在面前,只有金甲加身,付出汗水才能获得高薪,最后送大家一句话,不忘初心,方得始终。



猜你喜欢LIKE

相关推荐HOT
更多>>
索引有什么作用?在mongodb中索引分为几类
索引(Index)是数据库中的一种数据结构,用来提高数据检索的效率。它们可以帮助数据库系统快速地定位和访问需要的数据。在 MongoDB 中,索引也很...详情>>
2023-04-11 13:43:47
主键约束是什么意思?如何实现mysql主键约束
主键约束是一种在数据库中用于保证表中某个列的唯一性和非空性的约束,该列将成为表的主键。主键的作用是为了唯一标识表中的每一行数据,以方便...详情>>
2023-03-17 16:51:01
eureka和zookeeper的区别对比
Eureka和Zookeeper都是服务发现和注册的工具,但它们有以下几个不同点:架构设计:Eureka采用了集中式的架构,其中一个服务作为Eureka Server,...详情>>
2023-03-07 15:35:18
Zookeeper和Eureka的区别都有哪些?
Zookeeper和Eureka都是分布式系统中常用的服务发现和注册组件,它们的主要区别如下:数据一致性:Zookeeper是一个高度可靠的分布式数据一致性解...详情>>
2023-03-07 15:26:19
zookeeper和eureka的区别介绍
1.架构设计:ZooKeeper是一个分布式的协调服务,它提供了高可用、高可靠性的数据存储和协调服务,可以作为分布式系统中的一个通用组件使用。而E...详情>>
2023-03-03 15:00:46









 京公网安备 11010802030320号
京公网安备 11010802030320号