


大数据实时计算引擎Spark笔试题:Spark Catalyst查询优化器原理
小千今天分享的这篇spark笔试题是sparkSQL的优化器catalyst,本质上它就是一个SQL查询的优化器,大家了解了它之后基本就能了解其他的SQL处理引擎的优化原理了。
*SQL优化器核心执行策略主要分为两个大的方向:基于规则优化(RBO)以及基于代价优化(CBO),基于规则优化是一种经验式、启发式地优化思路,更多地依靠前辈总结出来的优化规则,简单易行且能够覆盖到大部分优化逻辑,但是对于核心优化算子Join却显得有点力不从心。举个简单的例子,两个表执行Join到底应该使用BroadcastHashJoin 还是SortMergeJoin?当前SparkSQL的方式是通过手工设定参数来确定,如果一个表的数据量小于这个值就使用BroadcastHashJoin,但是这种方案显得很不优雅,很不灵活。基于代价优化就是为了解决这类问题,它会针对每个Join评估当前两张表使用每种Join策略的代价,根据代价估算确定一种代价最小的方案。
*我们这里主要说明基于规则的优化,略提一下CBO
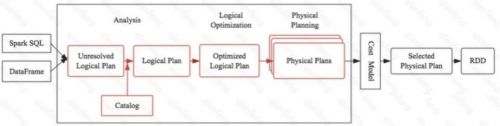
如上图是一个SQL经过优化器的最终生成物理查询计划的留存,红色部分是我们要重点说明的内容。大 家思考我们写的一个SQL最终如何在Spark引擎中转换成具体的代码执行的。任何一个优化器工作原理都大同小异:SQL语句首先通过Parser模块被解析为语法树,此棵树称为Unresolved Logical Plan; Unresolved Logical Plan通过Analyzer模块借助于数据元数据解析为Logical Plan;此时再通过各种基于规则的优化策略进行深入优化,得到Optimized Logical Plan;优化后的逻辑执行计划依然是逻辑的,并不能被Spark系统理解,此时需要将此逻辑执行计划转换为Physical Plan;为了更好的对整个过程进行理解,下文通过一个简单示例进行解释。
Parser
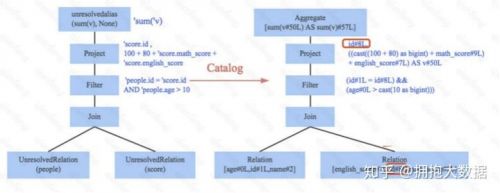
Parser简单来说是将SQL字符串切分成一个一个Token,再根据一定语义规则解析为一棵语法树。Parser模块目前基本都使用第三方类库 ANTLR 进行实现,比如Hive、 Presto、SparkSQL等。下图是一个示例性的SQL语句(有两张表,其中people表主要存储用户基本信息,score表存储用户 的各种成绩),通过Parser解析后的AST语法树如下图所示:
Analyzer
通过解析后的逻辑执行计划基本有了⻣架,但是系统并不知道score、sum这些都是些什么⻤,此 时需要基本的元数据信息来表达这些词素,最重要的元数据信息主要包括两部分:表的Scheme和 基本函数信息,表的scheme主要包括表的基本定义(列名、数据类型)、表的数据格式(Json、Text)、表的物理位置等,基本函数信息主要指类信息。
Analyzer会再次遍历整个语法树,对树上的每个节点进行数据类型绑定以及函数绑定,比如people 词素会根据元数据表信息解析为包含age、id以及name三列的表,people.age会被解析为数据类型 为int的变量,sum会被解析为特定的聚合函数,如下图所示:
Optimizer
优化器是整个Catalyst的核心,上文提到优化器分为基于规则优化和基于代价优化两种,此处只介 绍基于规则的优化策略,基于规则的优化策略实际上就是对语法树进行一次遍历,模式匹配能够满 足特定规则的节点,再进行相应的等价转换。因此,基于规则优化说到底就是一棵树等价地转换为 另一棵树。SQL中经典的优化规则有很多,下文结合示例介绍三种比较常⻅的规则:谓词下推(Predicate Pushdown)、常量累加(Constant Folding)和列值裁剪(Column Pruning)
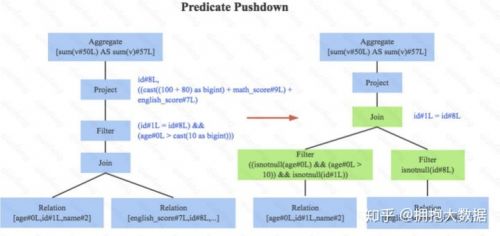
1.谓词下推, 下图左边是经过Analyzer解析后的语法树,语法树中两个表先做join,之后再使用age>10对结果进行过滤。大家知道join算子通常是一个非常耗时的算子,耗时多少一般取决于参与join的两个表的大小,如果能够减少参与join两表的大小,就可以大大降低join算子所需 时间。谓词下推就是这样一种功能,它会将过滤操作下推到join之前进行,下图中过滤条件age>0以及id!=null两个条件就分别下推到了join之前。这样,系统在扫描数据的时候就对数据 进行了过滤,参与join的数据量将会得到显著的减少,join耗时必然也会降低。
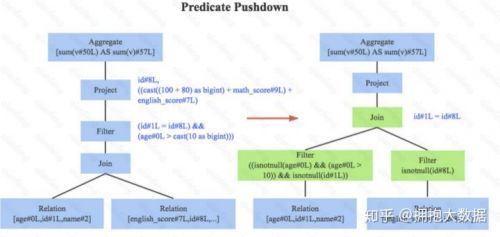
2.常量累加,如下图。 常量累加其实很简单,就是 x+(1+2) -> x+3 这样的规则,虽然是一个很小的改动,但是意义巨大。示例如果没有进行优化的话,每一条结果都需要执行一次100+80的操作,然后再与变量math_score以及english_score相加,而优化后就不需要再执行100+80操作。
3.列值裁剪,如下图。这是一个经典的规则,示例中对于people表来说,并不需要扫描它的所有列值,而只需要列值id,所以在扫描people之后需要将其他列进行裁剪,只留下列id。这个 优化一方面大幅度减少了网络、内存数据量消耗,另一方面对于列存数据库(Parquet)来说 大大提高了扫描效率
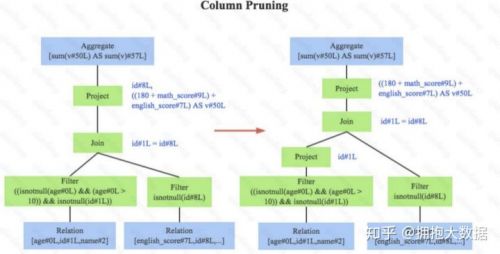
物理计划
经过上述步骤,逻辑执行计划已经得到了比较完善的优化,然而,逻辑执行计划依然没办法真正执行,他们只是逻辑上可行,实际上Spark并不知道如何去执行这个东⻄。比如Join只是一个抽象概 念,代表两个表根据相同的id进行合并,然而具体怎么实现这个合并,逻辑执行计划并没有说明。
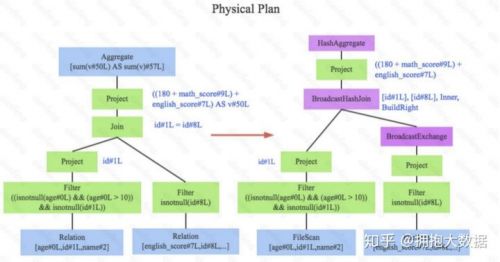
此时就需要将逻辑执行计划转换为物理执行计划,将逻辑上可行的执行计划变为Spark可以真正执 行的计划。比如Join算子,Spark根据不同场景为该算子制定了不同的算法策略,有BroadcastHashJoin、ShuffleHashJoin以及SortMergeJoin等(可以将Join理解为一个接口, BroadcastHashJoin是其中一个具体实现),物理执行计划实际上就是在这些具体实现中挑选一个耗时最小的算法实现,这个过程涉及到基于代价优化(CBO)策略,所谓基于代价 , 是因为物理执行计划的每一个节点都是有执行代价的,这个代价主要分为两部分
第一部分:该执行节点对数据集的影响,或者说该节点输出数据集的大小与分布(需要去采集)
第二部分:该执行节点操作算子的代价(相对固定,可用规则来描述)
在SQL 执行之前会根据代价估算确定一种代价最小的方案来执行。我们这里以Join为例子做个简单说明
*在 Spark SQL 中 ,Join 可 分 为 Shuffle based Join 和 BroadcastJoin 。 Shuffle basedJoin 需要引入 Shuffle,代价相对较高。BroadcastJoin 无须 Join,但要求至少有一张表足够小,能通过 Spark 的 Broadcast 机制广播到每个 Executor 中。
*在不开启 CBO 中,Spark SQL 通过 spark.sql.autoBroadcastJoinThreshold 判断是否启用BroadcastJoin。其默认值为 10485760 即 10 MB。并且该判断基于参与 Join 的表的原始大小。
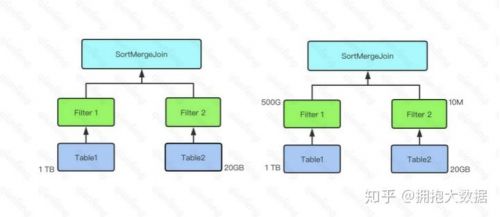
*在下图示例中,Table 1 大小为 1 TB,Table 2 大小为 20 GB,因此在对二者进行 join 时,由于二者都远大于自动 BroatcastJoin 的阈值,因此 Spark SQL 在未开启 CBO 时选用 SortMergeJoin 对二者进行 Join。
*而开启 CBO 后,由于 Table 1 经过 Filter 1 后结果集大小为 500 GB,Table 2 经过 Filter 2后结果集大小为 10 MB 低于自动 BroatcastJoin 阈值,因此 Spark SQL 选用 BroadcastJoin。
学习大数据开发,可以参考千锋大数据培训班提供的大数据学习路线,千锋大数据培训机构的学习路线提供完整的大数据开发知识体系,内容包含Linux&&Hadoop生态体系、大数据计算框架体系、云计算体系、机器学习&&深度学习。根据千锋大数据培训班提供的大数据学习路线图可以让你对学习大数据需要掌握的知识有个清晰的了解,并快速入门大数据开发。想要获取免费的大数据学习资料可以添加我们的大数据技术交流qq群:857910996,加群找管理领取即可,有任何大数据相关问题也可以加群解决,等你来哦~~



猜你喜欢LIKE

相关推荐HOT
更多>>
索引有什么作用?在mongodb中索引分为几类
索引(Index)是数据库中的一种数据结构,用来提高数据检索的效率。它们可以帮助数据库系统快速地定位和访问需要的数据。在 MongoDB 中,索引也很...详情>>
2023-04-11 13:43:47
主键约束是什么意思?如何实现mysql主键约束
主键约束是一种在数据库中用于保证表中某个列的唯一性和非空性的约束,该列将成为表的主键。主键的作用是为了唯一标识表中的每一行数据,以方便...详情>>
2023-03-17 16:51:01
eureka和zookeeper的区别对比
Eureka和Zookeeper都是服务发现和注册的工具,但它们有以下几个不同点:架构设计:Eureka采用了集中式的架构,其中一个服务作为Eureka Server,...详情>>
2023-03-07 15:35:18
Zookeeper和Eureka的区别都有哪些?
Zookeeper和Eureka都是分布式系统中常用的服务发现和注册组件,它们的主要区别如下:数据一致性:Zookeeper是一个高度可靠的分布式数据一致性解...详情>>
2023-03-07 15:26:19
zookeeper和eureka的区别介绍
1.架构设计:ZooKeeper是一个分布式的协调服务,它提供了高可用、高可靠性的数据存储和协调服务,可以作为分布式系统中的一个通用组件使用。而E...详情>>
2023-03-03 15:00:46


大数据培训问答更多>>
新大数据都学什么?5大核心知识必学内容有哪些
新大数据报班多少钱?如何选择培训机构
新人工智能学什么?自学可以成才吗
新数据处理包括哪些内容?是不是所有课程需要分别报课
新大数据分析需要学什么?怎么学比较好
新人工智能专业学什么?人工智能有哪些课程
新大数据数据分析师要学什么?好就业吗
大数据面试题库 更多>>




大数据的五个V是什么?
数据及集群管理(三)
数据及集群管理(二)
数据及集群管理(一)
大数据之hbase的优化读数据方面
大数据之hbase的优化写入数据方面
- 北京校区
- 大连校区
- 广州校区
- 成都校区
- 杭州校区
- 长沙校区
- 合肥校区
- 南京校区
- 上海校区
- 深圳校区
- 武汉校区
- 郑州校区
- 西安校区
- 青岛校区
- 重庆校区
- 太原校区
- 沈阳校区
- 南昌校区
- 哈尔滨校区



 京公网安备 11010802030320号
京公网安备 11010802030320号