


MapReduce排序问题
Hadoop MapReduce,作为分布式计算的第一代引擎,其经典的地位是不容动摇的,而越是经典越是有代表性的东西,也就越需要去深入理解其中的原理和运行机制。今天的大数据开发分享,我们主要来讲讲MapReduce排序问题。

排序是MapReduce的灵魂,MapReduce在Map和Reduce的两个阶段当中,都在反复地执行排序。
快速排序和归并排序
在MapReduce中有两种排序方式,分别是快速排序和归并排序——
快速排序:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
归并排序:归并排序(MERGE-SORT)是建立在归并操作上的一种有效的排序算法,该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。
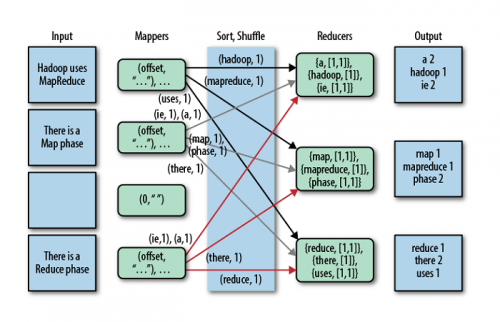
MapReduce过程中的几次排序
在MapReduce的shuffle过程中通常会执行三次排序,分别是:
Map的溢写阶段:根据分区以及key进行快速排序
Map的合并溢写文件:将同一个分区的多个溢写文件进行归并排序,合成大的溢写文件
Reduce输入阶段:将同一分区,来自不同Map task的数据文件进行归并排序
此外,在MapReduce整个过程中,默认是会对输出的KV对按照key进行排序的,而且是使用快速排序。
Map输出的排序,其实也就是上面的溢写过程中的排序。
Reduce输出的排序,即Reduce处理完数据后,MapReduce内部会自动对输出的KV按照key进行排序。
MapReduce如何执行排序?
在Map端:
每个Map任务都有一个环形的内存缓冲区用于存储任务输出。缓冲区达到一定的阈值(默认80%),一条后台线程便开始把内容溢出(spill)到磁盘。每次内存缓冲区达到溢出阈值,就会新建一个溢出文件(spill file)。
在写磁盘之前,线程首先根据数据最终要传的Reduce把数据划分成相应的分区(partition)。在每个分区中,后台线程按键进行内存中排序(排序是在Map端进行的)。如果有combiner函数就会在排序后的输出上运行,为了让Map输出结果更加紧凑。
在任务完成之前,溢出文件被合并成一个已分区且已排序的输出文件。如果溢出文件多于设置的数量,combiner就会在输出文件写到磁盘之前再次运行。
在Reduce端:
复制阶段,如果Map的输出相当小,会被复制到Reduce任务的JVM内存中;否则Map输出被复制到磁盘。随着磁盘上副本增多,后台线程会将它们合并为更大的、排好序的文件。
排序阶段,准确的说是合并阶段。复制完成Map的输出后,将合并Map输出,维持其顺序排序。最后一趟的合并来自内存和磁盘片段。
Reduce阶段,执行Reduce任务,把最后一趟合并的数据直接输入Reduce函数,从而省略了一次磁盘往返行程。
关于大数据开发,MapReduce排序的相关问题,以上就为大家做了详细的介绍了。MapReduce在运行过程中,排序是一个重要的操作,理解了排序对于MapReduce计算流程也会有更清晰的认识。
【免责声明】本文部分系转载,转载目的在于传递更多信息,并不代表本网赞同其观点和对其真实性负责。如涉及作品内容、版权和其它问题,请在30日内与联系我们,我们会予以更改或删除相关文章,以保证您的权益!此页面下方声明无效!



猜你喜欢LIKE




相关推荐HOT
更多>>
HDFS架构演进之路
当active Namenode出现故障或者宕机的时候,standby会自动切换为新的active Namenode对外提供服务,并且HA对外提供了统一的访问名称,对于用户...详情>>
2022-12-09 15:44:00
大数据开发:Hive小文件合并
Hadoop生态技术体系下,负责大数据存储管理的组件,涉及到HDFS、Hive、Hbase等。Hive作为数据仓库工具,最初的存储还是落地到HDFS上,这其中就...详情>>
2022-12-09 15:42:00
HDFS的故障恢复和高可用
客户端读取文件时,会先校验该信息文件与读取的文件,如果校验出错,便请求到另一DataNode读取数据,同时向NameNode汇报,以删除和复制这个数据...详情>>
2022-12-09 15:41:00
大数据开发:Flink on Yarn原理
这个Container通过Application Master启动进程,Application Master里面运行的是Flink程序,即Flink-Yarn ResourceManager和JobManager。详情>>
2022-12-09 15:39:00
大数据开发基础:Java基础数据类型
在Java基础入门学习阶段,Java基础数据类型无疑是基础当中的重点,掌握基础数据类型,对于后续去理解和掌握更深入的理论,是有紧密的关联性的。...详情>>
2022-12-09 15:38:13








 京公网安备 11010802030320号
京公网安备 11010802030320号