


HDFS文件管理系统简介
Hadoop作为大数据主流的基础架构选择,至今仍然占据着重要的地位,而基于Hadoop的分布式文件系统HDFS,也在大数据存储环节发挥着重要的支撑作用。今天的大数据入门分享,我们就主要来讲讲HDFS分布式文件管理系统。

一、HDFS文件管理系统
根据物理存储形态,数据存储可分为集中式存储与分布式存储两种。集中式存储以传统存储阵列(传统存储)为主,分布式存储(云存储)以软件定义存储为主。
传统存储:一向以可靠性高、稳定性好,功能丰富而著称,但与此同时,传统存储也暴露出横向扩展性差、价格昂贵、数据连通困难等不足,容易形成数据孤岛,导致数据中心管理和维护成本居高不下。
分布式存储:将数据分散存储在网络上的多台独立设备上,一般采用标准x86服务器和网络互联,并在其上运行相关存储软件,系统对外作为一个整体提供存储服务。
数据量越来越多,在一个操作系统管辖的范围存不下了,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,因此需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统。
常见的分布式文件系统有GFS、HDFS、Lustre、Ceph、GridFS、mogileFS、TFS、FastDFS等,而HDFS作为Hadoop的核心组件之一,在市场主流的使用非常普遍。
二、HDFS文件系统的特点
优点:
(1)高容错性。数据自动保存多个副本。通过增加副本的形式,提高容错性,某一个副本丢失,可以自动恢复。
(2)适合大规模的数据、文件处理。
(3)采用流式的数据访问方式,一次存入多次读取,存入的数据只能追加,不能修改。
(4)可以部署在廉价的机器上。
缺点:
(1)不适合低延时的数据访问,对延时要求在毫秒级别的应用,不适合采用HDFS。HDFS是为高吞吐数据传输设计的,因此可能牺牲延时。HBase更适合低延时的数据访问。
(2)无法高效地对大量小文件进行存储。文件的元数据(如目录结构,文件block的节点列表,block-node mapping)保存在NameNode的内存中,整个文件系统的文件数量会受限于NameNode的内存大小。
(3)无法支持并发写入。一个文件只能有一个写,不允许多个线程同时写入。
(4)不支持文件随机修改,仅支持文件追加。
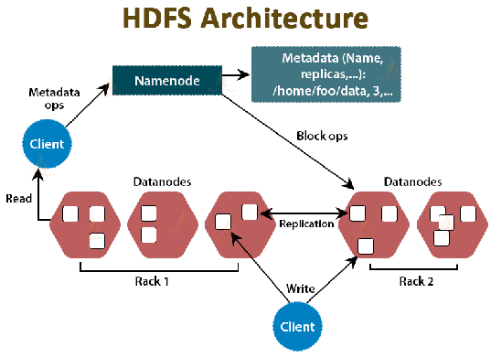
五、HDFS文件系统常用命令
命令行的交互主要通过hadoop fs来操作。
1、显示目录信息
#显示根目录下所有文件和目录
hadoop fs-ls/
#递归显示根目录下所有文件和目录
hadoop fs-ls-R/
2、将本地文件或目录上传到HDFS
#hdfs dfs-put<本地文件路径><hdfs路径>
hdfs dfs-put ceshi.txt/opt/data
copyFromLocal命令同样用于上传文件
hdfs dfs-copyFromLocal./ceshi.txt/opt/data
3、将文件或目录从HDFS中的路径拷贝到本地
hdfs dfs-get/opt/data/ceshi.txt/usr/local
copyToLocal命令同样可以实现从HDFS中的路径拷贝到本地
hdfs dfs-copyToLocal/opt/data/ceshi.txt/usr/local
4、将文件或目录从HDFS的源路径移动到目标路径
不允许跨文件系统移动文件。
hdfs dfs-mv/opt/data/ceshi.txt/opt/local
5、将文件或目录复制到目标路径下
hdfs dfs-cp[-f][-p|-p[topax]]URI[URI…]
选项:
-f选项覆盖已经存在的目标。
-p选项将保留文件属性[topx](时间戳,所有权,权限,ACL,XAttr)。
6、删除一个文件或目录
hdfs dfs-rm[-f][-r|-R][-skipTrash]URI[URI…]
选项:
如果文件不存在,-f选项将不显示诊断消息或修改退出状态以反映错误。
-R选项以递归方式删除目录及其下的任何内容。
-r选项等效于-R。
-skipTrash选项将绕过垃圾桶(如果已启用),并立即删除指定的文件。当需要从超配额目录中删除文件时,这非常有用。
7、追加一个文件到已存在的文件末尾
hadoop fs-appendToFile...
hadoop fs-appendToFile./ce.txt/opt/data/ceshi.txt
8、显示文件内容-cat
9、显示文件的末尾-tail
10、合并下载多个文件
#将HDFS的/opt/data目录下的文件合并为hb.txt文件并下载到本地
hadoop dfs-getmerge/opt/data/hb.txt
合并后的文件位于当前目录,不在hdfs中,是本地文件。
11、统计文件系统的可用空间信息-df
12、显示给定目录中包含的文件和目录的大小或文件的长度
hdfs dfs-du/opt/data/
HDFS作为Hadoop原生的核心组件之一,也是大数据学习当中的一块重点,分布式文件管理系统HDFS,需要深入去理解和掌握
注:本文部分文字和图片来源于网络,如有侵权,请联系删除。版权归原作者所有!此页面下方声明无效!

猜你喜欢LIKE



相关推荐HOT
更多>>
HDFS架构演进之路
当active Namenode出现故障或者宕机的时候,standby会自动切换为新的active Namenode对外提供服务,并且HA对外提供了统一的访问名称,对于用户...详情>>
2022-12-09 15:44:00
大数据开发:Hive小文件合并
Hadoop生态技术体系下,负责大数据存储管理的组件,涉及到HDFS、Hive、Hbase等。Hive作为数据仓库工具,最初的存储还是落地到HDFS上,这其中就...详情>>
2022-12-09 15:42:00
HDFS的故障恢复和高可用
客户端读取文件时,会先校验该信息文件与读取的文件,如果校验出错,便请求到另一DataNode读取数据,同时向NameNode汇报,以删除和复制这个数据...详情>>
2022-12-09 15:41:00
大数据开发:Flink on Yarn原理
这个Container通过Application Master启动进程,Application Master里面运行的是Flink程序,即Flink-Yarn ResourceManager和JobManager。详情>>
2022-12-09 15:39:00
大数据开发基础:Java基础数据类型
在Java基础入门学习阶段,Java基础数据类型无疑是基础当中的重点,掌握基础数据类型,对于后续去理解和掌握更深入的理论,是有紧密的关联性的。...详情>>
2022-12-09 15:38:13









 京公网安备 11010802030320号
京公网安备 11010802030320号